Spreadsheets with Empty Cells
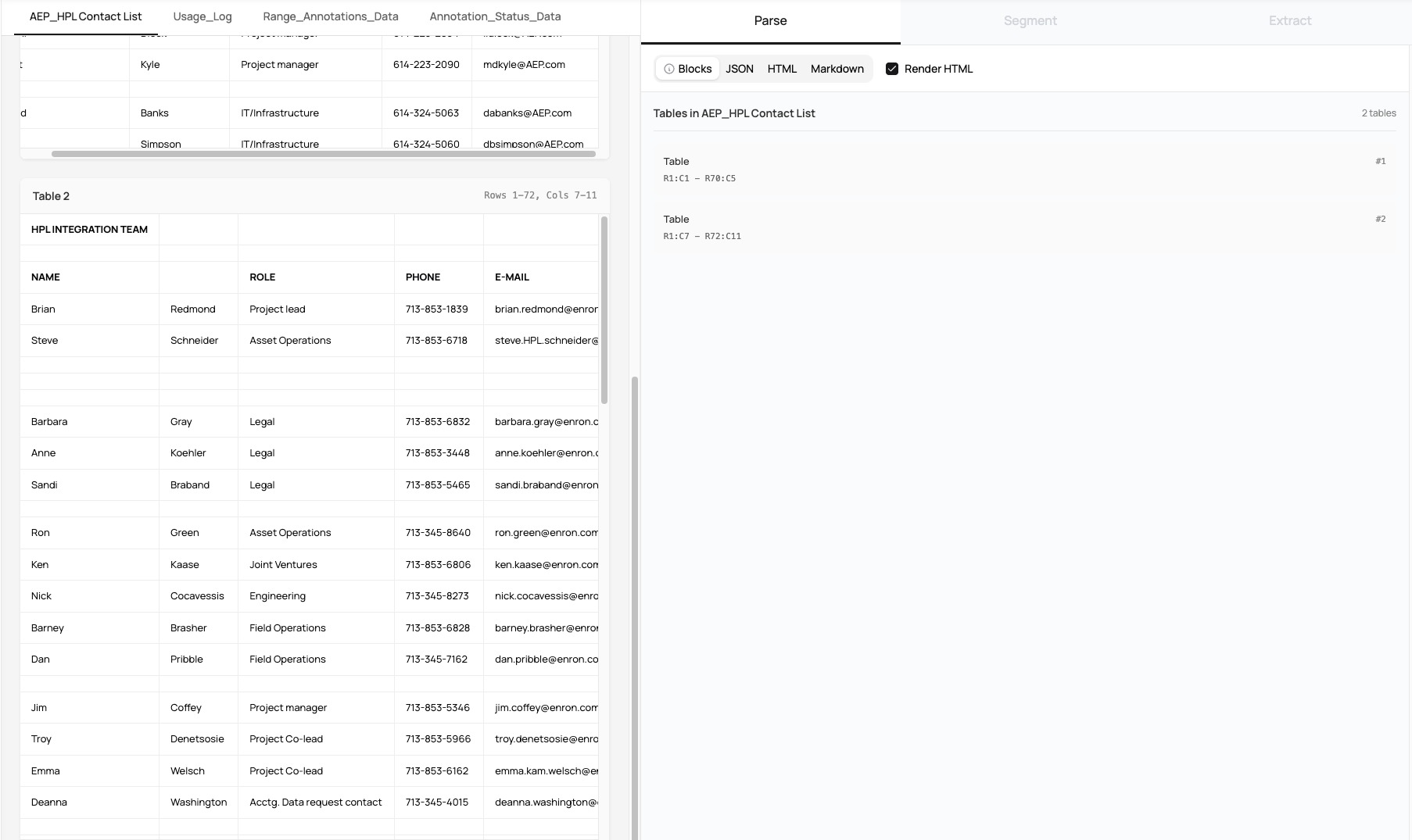
This example shows how Datalab parses spreadsheets and segments tables from a single sheet. The output identifies distinct table regions and returns them as structured blocks in JSON, HTML, or Markdown. Each block represents a complete table with its full context preserved, making it easier to extract, analyze, or route downstream.
At a glance, this spreadsheet we're parsing looks simple. It has two columns with gaps between rows. Many tools would treat this as one large table. Datalab correctly detects that the left and right columns represent separate tables and segments them accordingly.
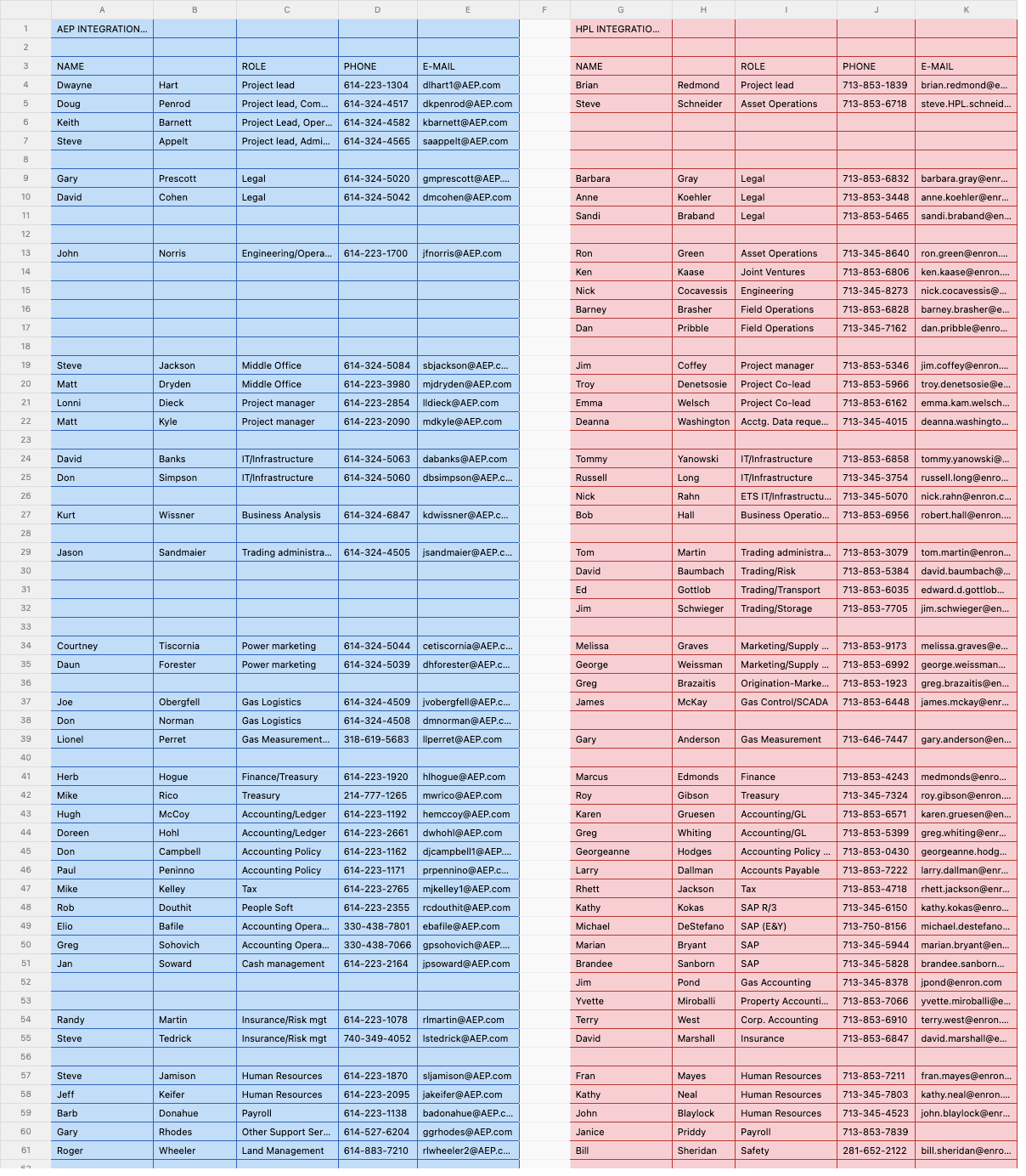
Spreadsheets appear structured because they use a grid. In practice, they have many of the same problems as PDFs.
A single sheet can contain multiple tables. Tables can be very long or very wide. Spacing and empty rows are often used to separate sections, but these gaps are inconsistent and unreliable. There is no semantic information stored in the file to indicate where one table ends and another begins.
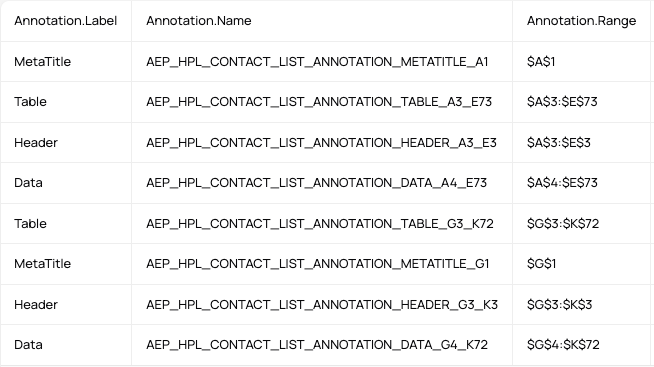
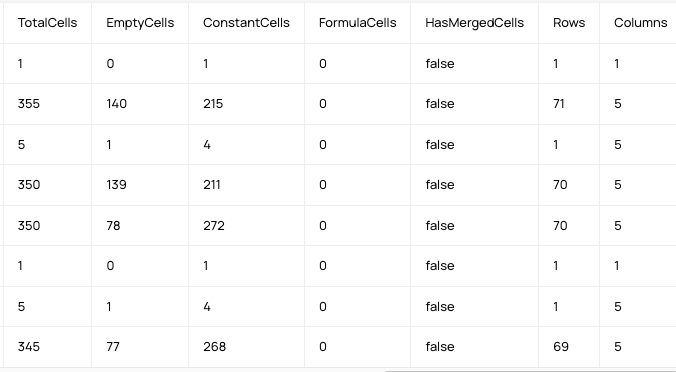
With the Datalab spreadsheet parser, we provide range annotation data that identifies content blocks by type, such as Table, Header, and Data. The output also includes details like annotation ranges, cell counts, and empty cell information. This makes it possible to understand how content is grouped instead of treating the entire sheet as one flat structure.
Even though spreadsheets are difficult to parse, they are critical to many workflows. Accurate parsing makes it possible to:
- Analyze financial spreadsheets across many portfolio companies at scale
- Ingest loss run spreadsheets from different carriers and standardize the data
- Normalize vendor price lists that all use different formats
Running OCR on spreadsheet images does not solve this problem. You may capture text, but you lose table boundaries and context. You cannot reliably separate tables or understand what each section represents.
Datalab parses spreadsheets natively instead of flattening them or treating them as images. Tables are segmented into complete regions with clear boundaries and metadata. This allows each table to be processed, extracted, or indexed independently, without losing context or merging unrelated data.
The result is structured spreadsheet data that is reliable for downstream analysis and automation.



